Parse My CSV Data
Automating the Reading of Data in Corrupted CSV Format.
Loading data from CSV files is a very common task for data practitioners. Although most tables stored in this format are well structured, parsing errors can cause friction and hassle when converting them into a proper data frame.
Let’s consider the following example from the book Cleaning Data for Effective Data Science:
Student#,Last Name,First Name,Favorite Color,Age
1,Johnson,Mia,periwinkle,12
2,Lopez,Liam,blue,green,13
3,Lee,Isabella,,11
4,Fisher,Mason,gray,-1
5,Gupta,Olivia,9,102
6,,Robinson,,Sophia,,blue,,12
Loading this data directly using popular packages or CSV libraries will likely raise errors.
This happens even when heuristics and algorithms are used internally to detect the best parsing parameters, because the structure does not fully comply with CSV standard constraints.
ParserError: Expected 5 fields in line 3, saw 6
Upon inspection, certain entries raise concerns due to apparent inconsistencies or errors related to the parsing:
- The entry for the student with Student# 2 (Lopez, Liam) appears to have an extra value in the Favorite Color column, which looks like two values ('blue,green') have been merged.
- The last row contains superfluous commas, indicating a possible data ingestion issue. However, aside from this formatting concern, the entry itself seems valid, leading to a high confidence level in identifying the nature of this error.
Although this file is only a small example used for educational purposes, parsing errors such as malformed rows or inconsistent formatting are quite common in real-world CSV files.
In large datasets, even a small number of problematic rows can require manual attention. Depending on the number and variety of these errors, this can lead to wasted time and frustration.
This is why a copilot is helpful — to quickly scan and understand parsing errors. It can automate the reading process or, at the very least, reduce the time spent during preprocessing.
Effortless LLM-Based Workflow to Improve CSV Parsing
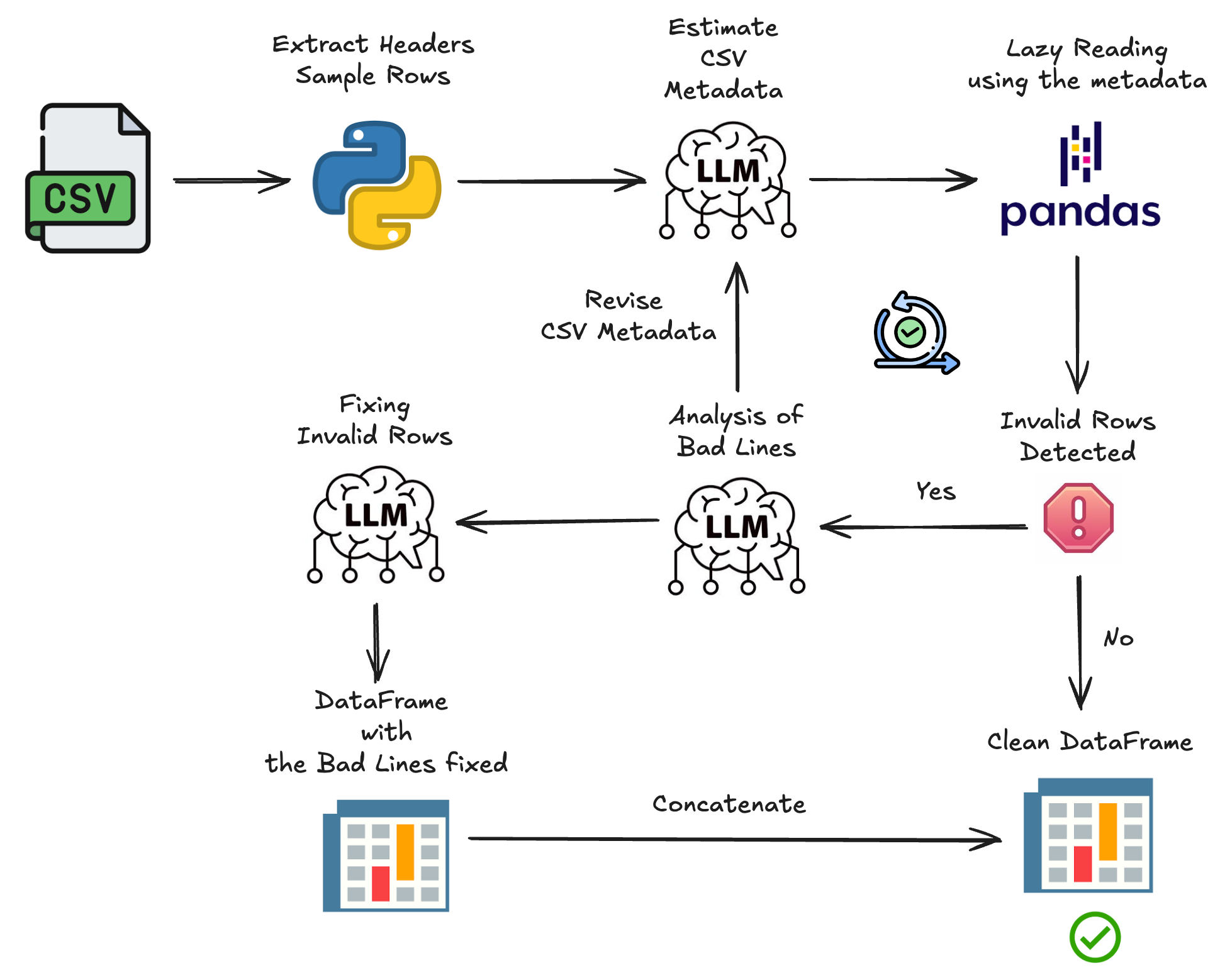
As each component is explained, output from the earlier dataset example will be shown to illustrate its purpose.
Estimating CSV Metadata from Headers and Sample Rows
The first step involves identifying key metadata needed to parse the CSV file correctly. Typically, the first few rows contain column descriptions, including the number and names of variables. Additionally, reading a few random rows helps understand the structure and formatting of the file.
This metadata is extracted using a large language model (LLM), guided by specific parameters:
- Encoding: The file’s character encoding (e.g. 'utf-8')
- Separator: The character used to separate fields (e.g. ',')
- Header: The row number to use as the header (0-indexed), or 'infer' to detect it automatically
- Names: An optional list of column names. If provided, the header is ignored
- Quotechar: The character used to quote fields (e.g. '"')
- Skiprows: The number of rows to skip at the beginning of the file.
These are the most common parameters needed to correctly load the majority of CSV files.
{
"encoding": "utf-8",
"sep": ",",
"header": 0,
"names": null,
"quotechar": """,
"skiprows": 0
}
Lazy Reading and Collection of Invalid Rows
The next step is to load the file gradually, building a DataFrame from valid rows while collecting the problematic ones for further inspection.
One common issue is that the initial metadata was based only on a sample of the data. After processing the full file, it may become clear that these assumptions were incorrect. In such cases, analysing the invalid lines with an LLM can suggest improved parameters. A new reading attempt is made using the revised metadata until parsing succeeds with minimal error.
Example:
Bad lines collected:
2,Lopez,Liam,blue,green,13
6,,Robinson,,Sophia,,blue,,12
Fixing Invalid Rows Based on Table Structure
Rather than discarding malformed rows, this step aims to repair them by aligning their values with the expected table schema. Each line is checked for inconsistencies, and the LLM proposes corrections where possible. If a line cannot be fixed reasonably, it is dropped.
Example:
Issues with lines:
- Line 2: Has 6 fields instead of 5 due to an extra "green" value
in the "Favorite Color" column.
- Line 6: Has 9 fields with many missing and misplaced values,
likely due to incorrect delimiters or extra commas.
Solutions:
- Line 2: Merge "blue" and "green" into a single "Favorite Color" value
as "blue, green" or choose one valid color.
- Line 6: Realign values to correct columns; based on context,
"Robinson" is the last name, "Sophia" is the first name,
"blue" is the favorite color, and "12" is age.
Repaired rows:
{
"Student#": 2,
"Last Name": "Lopez",
"First Name": "Liam",
"Favorite Color": "blue, green",
"Age": 13
},
{
"Student#": 6,
"Last Name": "Robinson",
"First Name": "Sophia",
"Favorite Color": "blue",
"Age": 12
}
Final DataFrame with Fixed Rows
After fixing any invalid lines, the cleaned and corrected rows are combined with the valid ones to produce the final DataFrame.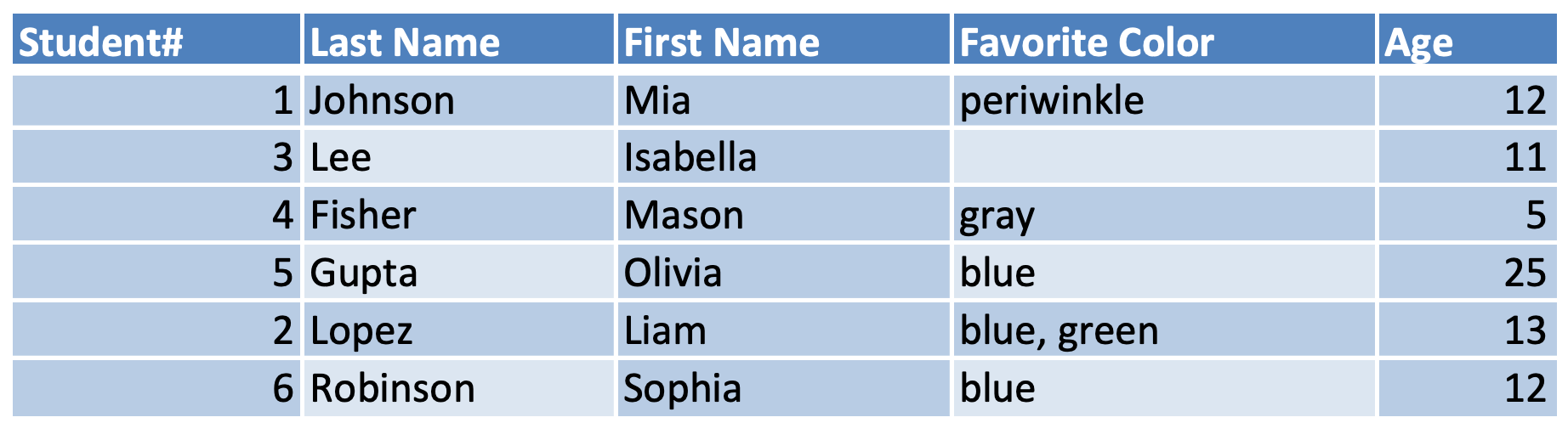
No information was lost in the conversion! 🎉